GA(遺伝的アルゴリズム、Genetic Algorithms)は、進化論的な考え方に基づいてデータを操作し、最適解探索や学習、推論を行う手法です。ここではGAの基礎知識を簡単に説明します。
GAで扱う情報
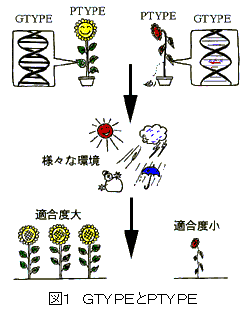
GAで扱うデータ構造は、GTYPE(genotype)とPTYPE(phenotype)の二層構造からなります。GTYPEは遺伝子型のアナロジーで、GAのオペレータ(後述)の操作対象となります。PTYPEは表現型(発現型)であり、GTYPEの環境内での行動や構造の発現を表します。また、PTYPEから環境に応じて適合度(fitness value)が決まります。以上を生物の絵にたとえて描くと、図1のようになります。
GAの基本的な仕組み
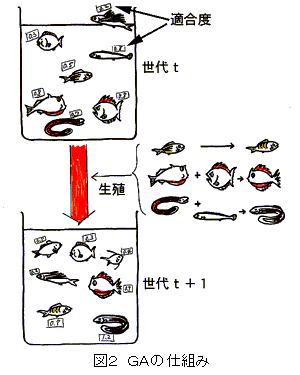
図2のように、いくつかの個体が集まって集団を構成しているとします。これを世代tの集団とします。個体にはそれぞれ適合度が決まっています。これらの個体は生殖活動(recombination、reproduction)を行い、次の世代t+1の子孫を作り出します。生殖の際には、適合度の高いものほど子孫をより多くつくるように、適合度の低いものほど死にやすいようにします(選択もしくは淘汰)。その結果、世代t+1の各個体の適合度は、世代tのそれよりも良いことが期待され、集団全体を見たときの適合度が上がっているはずです。同様に、世代t+1、t+2、…と繰り返していくと世代が上がるにつれ、次第に集団全体が良くなっていく、というのがGAの基本的な考え方となります。
GAにおける選択
- (1) ルーレット選択方式
- 適合度に比例した割合で個体を選択する方式です。これを実現する一番単純な方法は、適合度に比例した面積を有するルーレットをつくり、それを回して当たった場所の個体を選択するという方法です。
- (2) トーナメント選択方式
- 集団の中から個体をある個対数(トーナメントサイズ)だけランダムに選び出し、その中で適合度の最も高いものを選択します。この過程を集団数が得られるまで繰り返す選択方式のことです。この方式はトーナメントサイズの値で様々なバリエーションの選択が行えます。
- (3) エリート戦略
- 適合度の高い個体のいくつかを、そのまま次の世代に残すという手法です。適合度の高い個体が偶然選択されずに死滅することを防ぐことができます。これは上の2つと組み合わせて用いられます。
GAのオペレータ
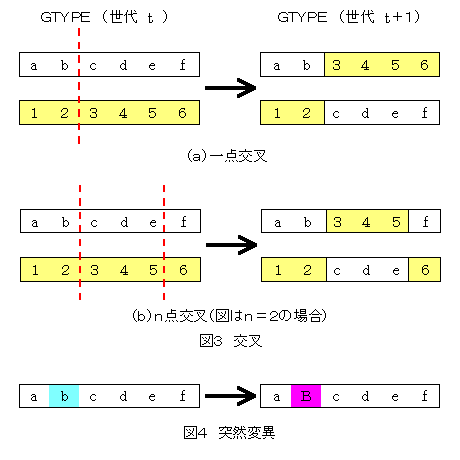
生殖の際には、GTYPEに対して図3、4に示す交叉(crossover)と突然変異(mutation)のオペレータ(遺伝子操作)が適用され、次の世代のGTYPEを生成します。図では簡単のためにGTYPEを1次元配列として表現しています。各オペレータは遺伝子の組換え、突然変異のアナロジーです。これらは、確率的に適用されます。
GAのアルゴリズム
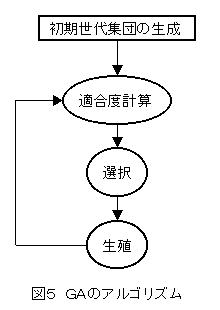
GAの基本的な流れをまとめると、次のようになります(図5)。
- 対象となる問題の解をGTYPEにコーディングする
- ランダムに初期世代を生成する
- 現在の集団の各個体について適合度を計算する
- 終了条件(世代数など)を判定する
- 現在の集団から適合度の高い個体を選択する
- 選択された個体にGAオペレータを作用させて、次の世代の集団を生成する
- Step3に戻る
私たちの研究室では
これらを適切に設計することで、遺伝的アルゴリズムは様々な分野に応用可能です。当研究室では、性選択、2倍体遺伝子とイントロン、共進化などによる遺伝的アルゴリズムの拡張を研究しています。